
About
The aim is to implement, test, and evaluate a Hardware Accelerator for Neural Networks (NN) using FPGA. The target NN application is to identify handwritten numbers. The chosen NN architecture is LeNet architecture.
Introduction
Computational resources are cheap nowadays, compared to several years ago. The latest 3nm technology supports a few hundred million transistors per square millimeter, increasing the computational resources for application. Still, general-purpose CPUs are performing badly in some applications. This is because, as said by the name, decades of design effort were put into making the CPU support various applications and run them fast but, the architecture suites for some applications more than the others hence the difference in performances. Exports soon understood the drawback of this "One design suits all" concept and started designing application-specific computers. This new branch in computer architecture is called Heterogeneous Computers aka Hardware Accelerators. A well-known Hardware Accelerator is the GPU, designed specifically for video applications.
While the GPU is very good at video data processing, the architecture is also good at Machine Learning (ML) tasks but isn't optimal. For this reason, GPUs are widely used in ML-related applications. There are companies that produce custom hardware targeted for NN. As an example, SambaNova Systems is one such company. Here the hardware is designed for high-bandwidth data flow, matrix multiplication, and high volume of RAM.
The proposed hardware accelerator for LeNet has also been designed with focusing on these factors. In addition, factors like the limitations of the available hardware, NN parameter quantization, reuse, and reconfiguration of hardware are also taken into consideration while designing.
Keywords
Hardware Accelerator, FPGA, CNN, LeNet, Image processing, Device Driver Development.
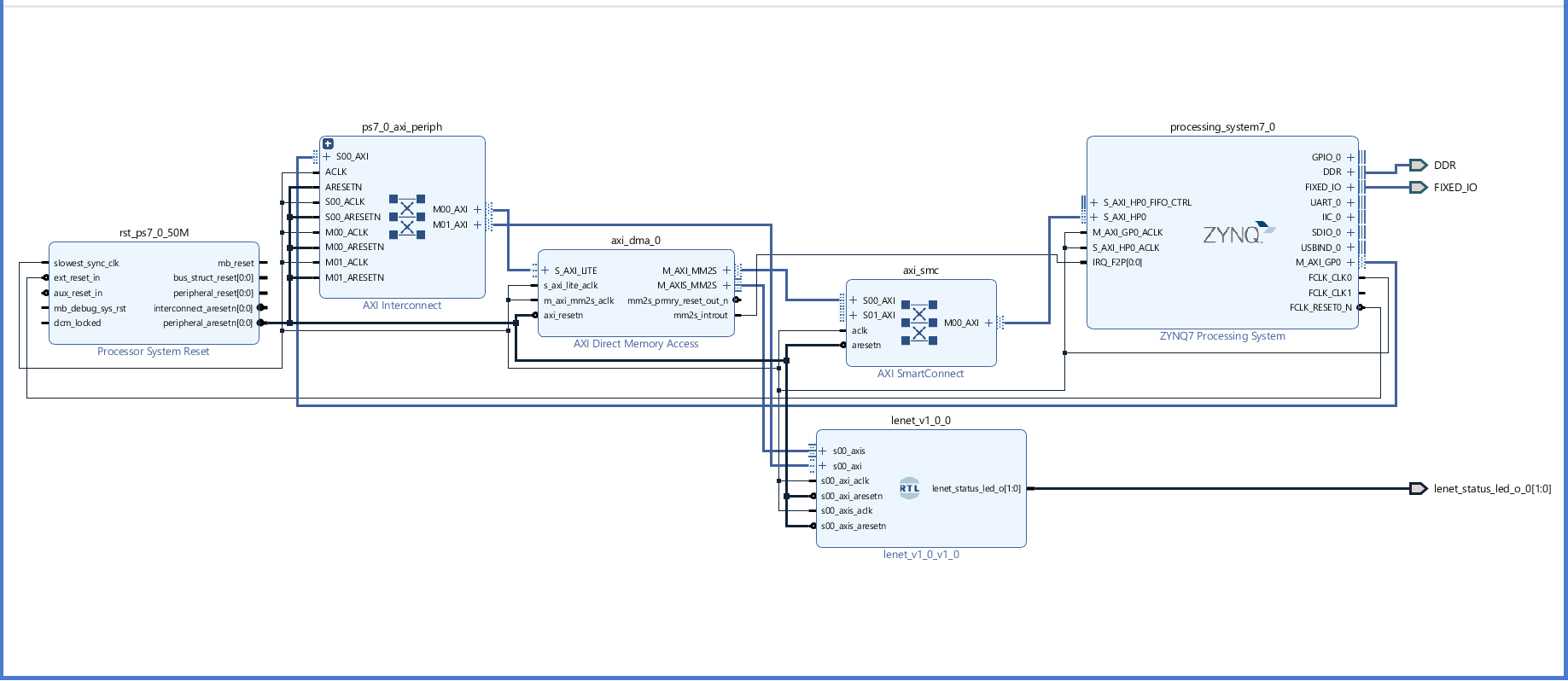
Block Design
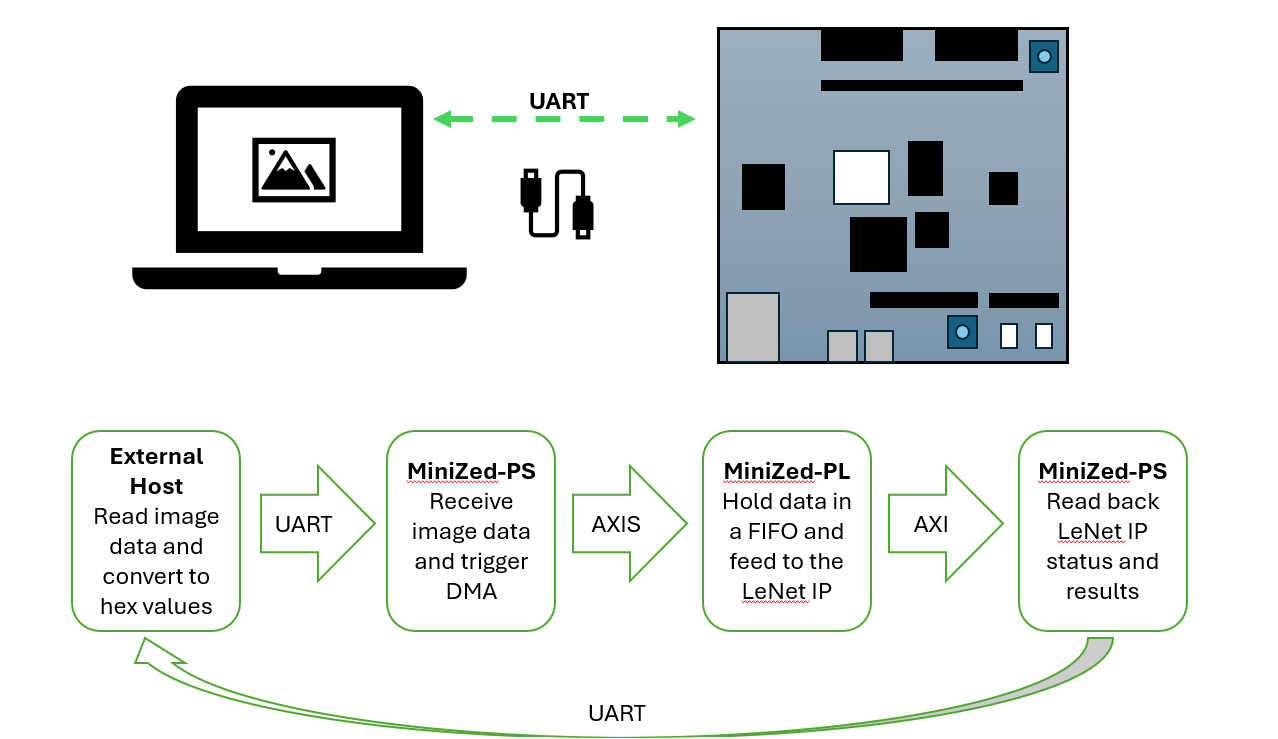
Communication flow

Run on Hardware
Implementation
The design processes started with an available software implementation of LeNet. The first step was to unwrap the software functions in the NN layers so they could be implemented on the hardware while validating the results. Then the NN parameter quantization was implemented as it is needed in a later step in hardware design. The quantization was done while minimizing the quantization error. The quantized NN parameters were saved to use in the hardware accelerator.
The next step was to implement the NN layer functions on hardware using Verilog. Mainly the CNN and the Dense layer were developed separately so they can operate independently. Block RAMs (BRAMs) were used to store the NN parameters and intermediate results. The quantized weights and biases produced earlier were used to initialize BRAMs. The CNN and the Dense layers were connected together and wrapped with an AXI Streaming (AXIS) interface and an AXI General interface forming a device peripheral (lenet_v1). The AXIS was used to send the image data to the lenet_v1 and the AXI General interface was used to control and read the lenet_v1 status. The lenet_v1 was implemented in the ZYNQ7000 programmable logic (PL) and connected to the ZYNQ7000 Processing System (PS) using direct memory access (DMA) and an AXI interconnect.
Finally, a software device driver was implemented using Vivado-SDK and C language. The device driver is capable of receiving UART data and triggering the DMA to start sending image data, read the status of the lenet_v1, read the lenet_v1 result, and reset the lenet_v1.
To find out more information and the source code, please visit my GitHub page.
Results
The PyTorch model
- Accuracy: 98.88%
- Run time: 1.5s
The quantized version of the software
- Accuracy: 98.01%
- Run time: 9min
The hardware version
- Accuracy: 84.33%
- Run time: 20min
The LeNet IP returns 84.33% accuracy when evaluated over 10000 images. Possible reasons for the accuracy drop can be the quantization and rounding errors. It is observed that different model parameters produced from several training events give similar accuracy in software but when deployed on hardware, they have a big difference in accuracy.
It takes around 20min to run all 10000 predictions with the communication flow mentioned above. The LeNet IP is idle most of the time, which can be seen by the active PL-LED connected to the IP and most of the time is consumed by the UART connection to receive data.
Live results can be viewed by using the JupyterNotebook script in the repository.